1. 三种架构总览
大语言模型现在有三种架构:Encoder-Only、Decoder-Only、Encoder-Decoder。《Attention Is All You Need》采用的是 Encoder-Decoder,而现如今几乎所有的大语言模型,包括 nanoGPT 都采用的是 Decoder-Only 架构。
三种架构的差异很大程度上由三类原因决定:Attention Mask 的机制、训练目标、数据流向(QKV 的来源):
| 架构 | Attention | Mask 机制 | 训练目标 |
|---|---|---|---|
| Encoder-Only | Bidirectional/Unmasked Self-Attention | 无 | “完型填空” |
| Decoder-Only | Causal/Masked/Unidirectional Self-Attention | Causal Mask | 预测下一个词 |
| Encoder-Decoder | Enc:双向 / Dec:单向 + Cross-Attention | Causal Mask (仅 Decoder) | Seq2Seq,通常是机器翻译 |
从预训练和微调阶段入手理解这三个框架可能会更直观一些。
2. Encoder-Only
由于不需要做 Causal Mask,Encoder-Only 能看到完整的上下文,具有很强的理解能力,但是生成能力相对较差。
2.1 预训练阶段(Pre-Training)
预训练阶段这一步的结果和其它架构类似,只是为了得到一个懂语言的“通用模型基座”,还不会做具体的分类和实体识别。
Encoder-Only 架构采用 Masked Language Modeling 进行训练,即虽然我们常说 Encoder-Only 能看到完整的上下文,但实际上依然会应用 Mask 技术来“挖词”。而挖词是为了在没有人工标注数据的情况下,让模型利用海量文本自己学习语言规律,完成无监督学习:
- Masked Language Modeling,掩码语言模型,随机把一些词替换成
[MASK]这种特殊 token - Encoder-Only 也需要做 Mask,只不过不需要像 Causal Mask 那样去遮挡未来信息
MLM 的“挖词”与 Encoder-Only 能看到完整的上下文并不矛盾,可以联系到后文的 Causal Mask,Causal Mask 只允许看到“过去”的信息,而 Encoder-Only 可以看到所有信息,无论是不是
[MASK]。下文中 Encoder-Decoder 中的 Encoder 部分做的 Span Corruption 同理。
预训练阶段的 Loss 只取 mask 的位置。
2.2 微调阶段(FT, Fine-Tuning)
微调阶段是有监督的,是在预训练阶段的基础上进行二次处理(增加简单的输出层)来完成。
Encoder-Only 通常不需要指令(Instruct)微调,但依然需要进行有监督的人工标注后的数据学习。我的理解是按照实际的应用场景来进行不同的微调。
-
例 1 - 文本分类:在所有句子前面强制加一个特殊的 token,经过 Transformer 处理之后输出向量矩阵,接着只取第一个 token 对应的输出向量与真正的分类来计算 Loss
-
例 2 - 实体识别:按照正常流程经过 Transformer 处理之后,增加一层全连接层,将每个词对应的视图作为 label,模型逐个位置计算 Loss 并求和
3. Decoder-Only
LLM 主流架构,几乎所有的大模型都是 Decoder-Only。
3.1 预训练阶段
Causal Mask
Decoder-Only 需要对 Scaled Scores 做 Causal Mask,即在 Softmax 之前:
- 必须在 Softmax 之前,这样经过 Softmax 才能将\(-\infty\)对应的概率权重变成0(\(e^{-\infty}=0\)),用于并行训练
- 同一个结果矩阵就包含了“只看前 1 个”、“只看前 2 个”、“只看前 3 个”等所有情况
这里有一个问题,对于 MaskedScores 的第一行,只看前 1 个的情况会不会无法收敛?答案是否定的,依然能够正常学习和收敛。模型的任务永远是拟合“当前数据”,全量数据训练完成之后,模型得到的也是“当前数据”的统计规律。
加权计算
借用李宏毅老师的一张 ppt:
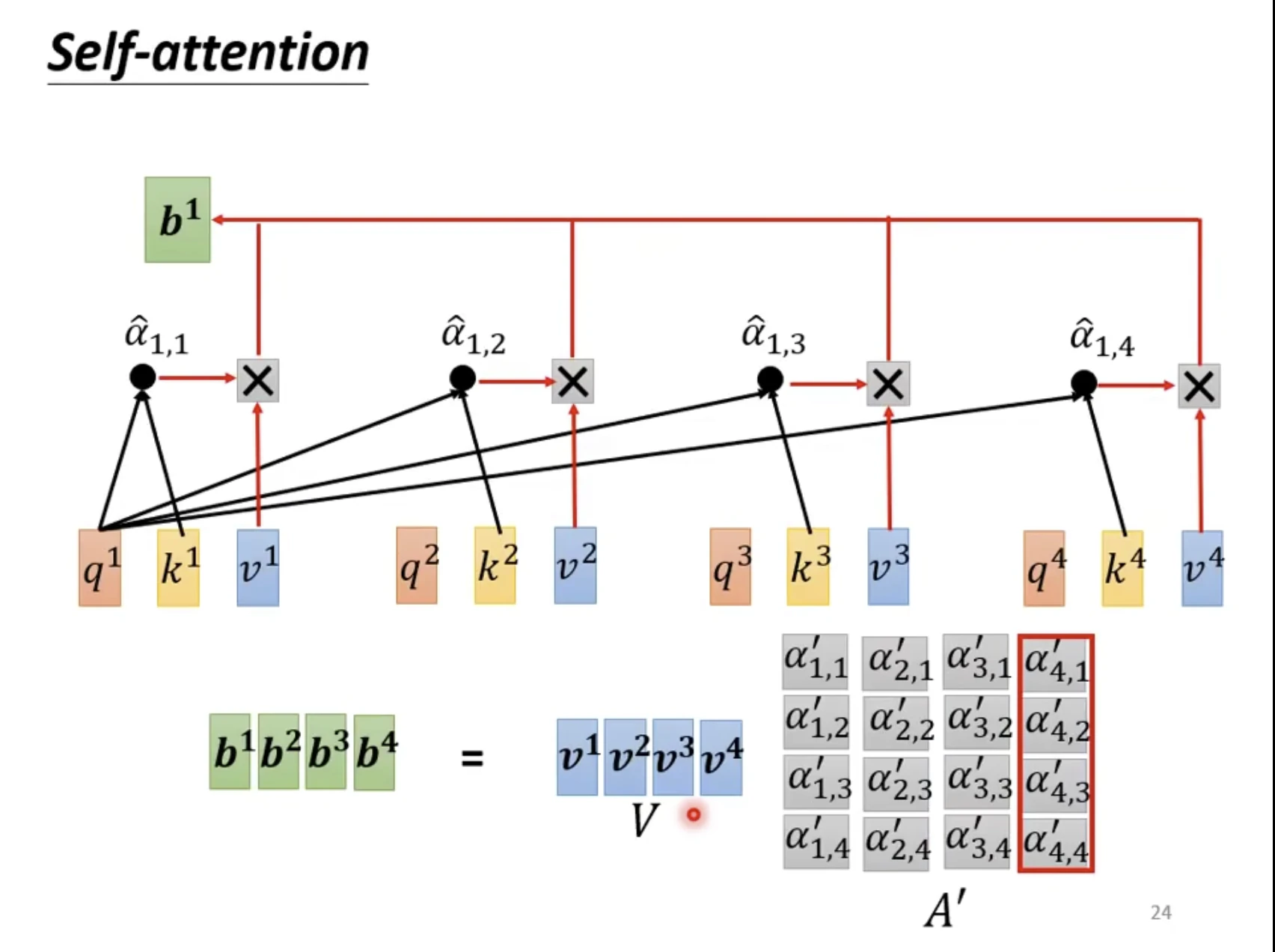
这一步是将得到的下三角矩阵 probs(右上角全零,对角线及左下角每行相加总和为 1)与 V 做矩阵乘法。
由于 V 矩阵不会被 Mask,因此结果矩阵的每一行都是完整的 token 对应的 embedding 数据。这个过程中的 shape 变化为:probs 的 shape 为 \(L\times L\),probs 与 V 相乘的结果回到\(L\times D\)。
我们以下面这两个矩阵举例:
-
\(probs \times V\) 结果的第一行即表示第一个 token 对自己的打分去与 V 的信息进行融合:
- 第一行:\(1.0⋅v_A+0⋅v_B+0⋅v_C=V_A\),物理意义为:我现在手里只有 A 的信息,用这个向量去预测 B
- 第二行:同理,\(0.2⋅v_A+0.8⋅v_B+0⋅v_C=0.2V_A+0.8V_B\),物理意义为:我是 B ,但我回顾了历史,融合了 A 和 B 的信息,用这个融合后的向量去预测 C
- 第三行:……
-
Scaled Attention Score 经过 Softmax 得到 mask 剩下的数值的行总和为 1 的概率;probs 与 V 相乘得到的 Attention Output 依然是稠密矩阵,因为是与完整的 embedding 维度相乘,真正融合上下文信息
-
Attention Output 的第一行对应的就是用于第一个 token 的下一个 token 的预测依据;Attention Score 在经过 FFN 以及多次堆叠的 block 重复操作之后,得到 \(H_{final}\),此时\(H_{final}\) 的第 i 行即是前 i 个 token 的上下文信息。接着,需要用 \(W_{vocab}\) (通常是前置的 Embedding 的转置,每一列严格对应行序相同的 Embedding 的一行),\(H_{final}\) 与 \(W_{vocab}\) 点乘的结果即是词表中每个 token 作为第 i+1 个 token 的得分,下一步经过 Softmax 得到对应的概率。
我之前把这里的步骤弄混过,所以也再次强调 Q 与 K 相乘过程中不需要进行 mask, K 的转置保证维度对齐,这一步侧重于当前 token 对其它 token 应该分配的注意力。Q 与 K 相乘后,Causal Mask 发生在对矩阵乘积的结果上,作用是只保留“过去”的上下文(不是 mask token 的部分 embedding 而是 mask 掉后续的 token)。
Attention Output 经过 FFN 与残差与 Norm 得到 \(H_{final}\),\(H_{final}\) 与 \(W_{vocab}\) 相乘得到每个位置的 token 作为下一个 token 的得分;从宏观的数据流向看,其实是 Q 与 K 与 V 与 W_vocab 相乘,用乘法作为得分,为了防止“作弊”所以做 Causal Mask,为了得到概率所以 Softmax。
CausalMask 是非常有必要的,必须先经过这一步才能进行这里的加权相乘(做“预测下一个词”的训练),不然模型会学到“只需要把输入的下一个词拷贝到输出”这样的错误规律。被 mask 之后,模型必须从海量训练数据中学习类似这样的通用规律:通常“我”后面接“爱”的概率比较大。
3.2 微调阶段
预训练阶段之后,Decoder-Only 模型会得到一个基础模型(Base Model),也就是常说的基模。Base Model 此时只会继续做续写任务(词语接龙)。
此时我们通常会进行指令微调,即 SFT。Decoder-Only 通常会采用 Prompt-Response 格式的指令微调(Instruction Tuning)。具体操作为,将用户的指令和对应的回答,用特殊字符拼接成一段单向的长文本,例如:<|user|>\n天空为什么是蓝色的?\n<|assistant|>\n因为瑞利散射。<|endoftext|>
无论是预训练还是微调,核心运算逻辑和网络架构(包括下三角的 Causal Mask)没有任何改变,也依然从左向右,一个词一个词地往下看,预训练与微调阶段的区别在于 Loss 的计算方式:微调阶段采用了 Loss Mask,来剥离掉 Prompt 对权重的影响。直白点说,用户的提问参与训练但是不参与学习/参数更新。
具体来说,Loss Mask 会给 Prompt 部分打成特殊的 label,最终计算 Loss 时遇到这些 label 会跳过,这些 label 的数量也不参与平均:
// 伪代码逻辑
float total_loss = 0.0;
int valid_count = 0; // 去除不参与 Loss 计算的数量
for (int i = 0; i < sequence_length; ++i) {
int target_label = labels[i];
// 核心判断:遇到 ignore_index,直接跳过计算
if (target_label == -100) {
continue;
}
// 计算有效 token 的 Loss
float current_loss
= compute_cross_entropy(logits[i], target_label);
total_loss += current_loss;
valid_count++;
}
return total_loss / valid_count;
从数学上,可以粗略地这样理解:当梯度反向传播更新权重时,根据依赖关系,Loss 依赖每个 token 的计算结果,每个 token 的计算结果又依赖前置的权重;由于 Loss 的公式中压根没有 Prompt 部分,因此链式法则的相应部分直接在数学上得到 0,也就不会对权重的更新造成影响。
不要搞混:梯度反向传播更新的是权重而不是节点!另外,这里暂不考虑 shift 的情况。
我们举一个简单的例子:假设我们有一句话,2 个词是 Prompt,2 个词是 Response:
- 输入序列:
[提问1, 提问2, 回答1, 回答2] - 模型输出(Logits):
[Z1, Z2, Z3, Z4] - 真实标签(Labels):
[-100, -100, Y3, Y4]
计算 Loss 时:
计算图上根本没有 Z1与 Z2 参与。我们以 \(\theta\) 统称前置需要更新的权重,根据依赖关系:
-
L 根本不依赖 Z1 与 Z2,所以当成常数,偏导值为 0:
\[\frac{\partial L}{\partial \theta} = 0 + 0 + \left( \frac{\partial L}{\partial Z_3} \cdot \frac{\partial Z_3}{\partial \theta} \right) + \left( \frac{\partial L}{\partial Z_4} \cdot \frac{\partial Z_4}{\partial \theta} \right)\] -
\(\theta\) 将继续被更新,但是跳过了 Prompt 的贡献
3.3 对齐阶段(Alignment)
只要具备文本生成的模型(Generative Models)都需要做对齐,但通常针对 Decoder-Only
即使经过微调,模型也可能说出有害或者不符合人类偏好的话(Helpful, Honest, Harmless),所以现代大模型还会经过 RLHF 或者 DPO(Direct Preference Optimization,直接偏好优化),用“这篇回答比那篇回答好”的偏好数据进一步调整模型权重。
对齐阶段有两条路线:经典的 RLHF 和 DPO 算法:
-
RLHF:以 ChatGPT 为代表。使用人类标注员参与裁判模型(Reward Model 裁判模型输出的结果质量越符合人类偏好,人类打分越高)的训练,接着用 SFT 模型去生成回答,RM 给回答打分,SFT 模型根据分数来更新自己的参数
- 为了防止模型刷高分,通过 KL 散度惩罚来防止 SFT 模型输出的概率偏离初始的 SFT 模型太远
-
DPO:更现代也更优雅,开源界常用,包括 Qwen和 Llama
- 不使用奖励模型和强化学习,只需要准备好人类偏好数据(一个好回答 Chosen,一个坏回答 Rejected),在训练时,直接调整 SFT 模型的参数,使得 SFT 模型生成好回答的概率变大,生成坏回答的概率变小,同时用初始的 SFT 模型做锚定
- 相比 SFT 的目标是预测正确下一个词,对齐阶段 DPO 的目标是扩大好坏回答的概率差;数据格式也不再是 SFT 阶段的 Prompt + Response,而是 Prompt + Chosen + Reject
4. Encoder-Decoder
我个人感觉 Encoder-Decoder 的应用场景较少,所以这个类型的架构以了解为主,不花过多时间深入。
4.1 预训练阶段
和 Encoder、Decoder 一样,预训练阶段的目标都是通过海量无标注数据,得到一个掌握了高维语言规律和世界知识的通用基座模型(Base Model)。
具体操作:通常对 Encoder 部分采用 Span Corruption,将输入句子中连续的几个词挖掉,替换成一个特殊的占位符,然后让 Decoder 去把挖掉的片段原封不动生成出来。即破坏(Corruption) 发生在 Encoder,而重建(Reconstruction)发生在 Decoder。
双重 Attention:同时包含 Self-Attention 与 Cross-Attention
-
Self-Attention:Encoder 做双向无 mask 的 Self-Attention,区别于 Encoder-Only, 这里做的是 Span Corruption 而不是 MLM;而 Decoder 继续做带 Causal Mask 的 Self-Attention
-
Cross-Attention:Encoder 的最后一层输出产出 K 和 V,Decoder 通过 Cross-Attention 读取 Encoder 整理好的残缺句子的特征,然后用自己当前输入的 Q 把那些“挖掉”的词还原出来
4.2 微调阶段
几乎都是 Seq2Seq,给出一段文本,根据翻译、总结或问答等不同场景,来让回答逼近给出的答案文本。
5. 小结
- 正因为 Decoder-Only 是“单向且自回归”的(下一个词依赖前面的词),这就导致了在推理(Inference)阶段,每次生成新词都需要重新计算前面所有词的 Attention。为了避免重复计算,Infra 层引入了 KV Cache 技术,将历史 token 的 Key 和 Value 矩阵缓存到显存中。这也意味着 Decoder-Only 模型的推理是一个典型的 Memory-Bound(访存密集型) 任务;
- Loss Mask 虽然剥离掉 Prompt 对权重的影响,但在前向传播中带来的开销是不可避免的。换句话说,Prompt 依然在前向传播中参与了庞大的矩阵乘法;
- RLHF 需要在显存中同时挂载 4 个模型(Actor, Reference, Reward, Critic),对 GPU 显存(VRAM)的要求极其恐怖。而 DPO 在数学上绕过了 Reward 模型,只需要挂载 2 个模型(Policy 和 Reference),大大降低了对齐阶段的硬件门槛,这也是 DPO 在开源社区如此火爆的重要底层原因之一。
0 条评论