1. 整体结构
model.py 的内容非常简单,加上文件开始的导入部分,总共只有 331 行。
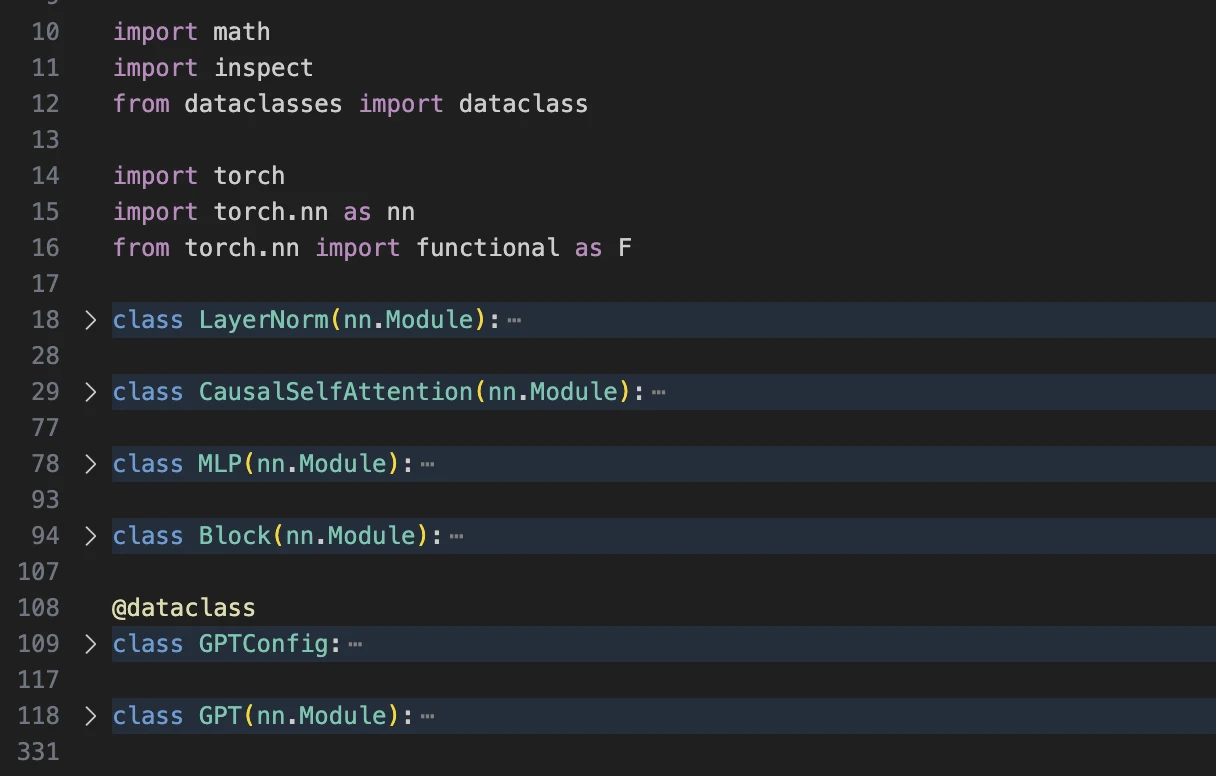
类之间的依赖关系如下:
GPT
├──▶ GPTConfig
├──▶ Block
│ ├──▶ CausalSelfAttention
│ ├──▶ MLP
│ └──▶ LayerNorm
│
└──▶ LayerNorm
不像 cpp 需要前置声明,Python 可以在不实际解析的地方使用 未声明/后置声明 的类。可能是出于 cpp 程序员的习惯,这个文件依然遵从了从小到大、从底层到上层的声明顺序。当然,这也是最佳实践。
关于 @dataclass
整个文件中有一处被 @dataclass 修饰的 GPTConfig 类非常显眼,这里存在一个 Python 上的语法陷阱。
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
dropout: float = 0.0
bias: bool = True
对于不被 @dataclass 修饰的类,如果在类内部且方法外部直接声明和定义一个变量(不带self,例如a = 10),那么意味着它就是一个类变量,相当于 cpp 的 static 成员,会被所有类实例共享。
而如果是带有类型注解的声明,例如a: int,那么它就只是一个排版注释,几乎没有作用。但是当这种类被 @dataclass 修饰后,通过这种方式声明的成员会自动成为 __init__ 方法中的 self 实例变量。因为 @dataclass 本质上是扫描所有变量并且按照变量的声明顺序自动写出一个 __init__ 方法,接着把所有的变量变为“类的实例不共享”(每个类的实例特有)的 self. 开头的实例变量。
用下面的例子总结,@dataclass 省去了手写麻烦的 __init__ 过程:
class Test1:
a = 10 # 类变量
class Test2:
a: int # 没有实际作用,且直接`Test2.a` 会报错,必须显式赋值(可以是 None)
@dataclass
class Test3:
a: int # 转化为类实例的成员,不能通过Test3.a读取,但是可以通过Test3().a读取
@dataclass 还重载了 __repr__,使得直接 print 打印的结果可读性更高;同时也重载了 operator==,当两个 @dataclass 数据相同时,将返回 True。
2. LayerNorm 的工程实现
class LayerNorm(nn.Module):
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
2.1 LayerNorm 与 BatchNorm
Transformer 的 LayerNorm 与 CNN 的 BatchNorm 有着非常大的不同。
两种 Norm 本身做的都是标准化(即让数据均值为 0,方差为 1),但是约定俗成的叫法是归一化。在李宏毅老师的视频里,我也看到他直接称之为 Norm,避免大家在理解上产生不必要的偏差。
归一化的目的都是为了让数据在某个维度上进行伸缩变化,将数据整体控制在某个区间内。一方面,可以加快模型的收敛;另一方面,也能减少方差过大的特征对训练的影响,提升模型的准确性。敬请参阅前置的博客,理解会更深刻。LayerNorm 与 BatchNorm 都在做这件事。
归一化并不会改变 tensor 的 shape,简化的归一化公式为: \(y = \frac{x - \mu}{\sigma}\) 为了避免除零异常,分母通常会带上一个极小的 \(\varepsilon\),这里为了方便就省略了。
注意:归一化的分母是标准差,这里也很好理解,方差的公式为 \(\frac{(x - \mu )^2}{n}\) ,因此单位会变为原本数据的平方。如果使用方差,那么分母为单位的平方,而分子 \(x-\mu\) 依然为原本单位会造成单位的不一致。
张量经过归一化还是得到张量,但是在这个过程中,我们需要的中间结果均值 \(\mu\) 与标准差 \(\sigma\) 的 shape 会与原始数据不同,具体来说:在所处理的维度上从张量变为标量;
以二维 CNN 为例,维度为 \((N, C, H, W)\),通道与通道之间我们通常认为是不同的量纲,例如经典的以三原色进行划分,通道 C 本身是三维的:R, G, B。BatchNorm 的做法是针对相同量纲进行归一化,因此 R 通道做一次归一化,G 通道做一次归一化,B 通道同理。因此在进行归一化的过程中,均值 \(\mu\) 与标准差 \(\sigma\) 的 shape 会从原始数据的 \((N, C, H, W)\) 变为 \((1, C, 1, 1)\) 。
之所以 Transformer 会使用 LayerNorm,而不是 BatchNorm。我是这样理解的,当我们在做经典的机器学习时,特征维度每一“列”基本上都是无关的,例如某一列代表身高、某一列代表性别、或者干脆回到上一段描述的某一列代表 R、某一列代表 G、某一列代表 B 等,沿着特征的维度去做伸缩是非常合理的。而在 Transformer/Embedding 中,并不是这样的,每个维度并不是完全独立的物理量,维度与维度之间存在关系,“所有的维度”共同组成这个 token 的高维语义空间。因此,LayerNorm 是针对每个 token (每行)来做归一化,对于维度 \((B, L, D)\) 的输入数据,LayerNorm 的中间结果会得到 shape 为 \((B, L, 1)\) 的结果。
上面用的是简化过的归一化公式,实际上归一化本身也存在可学习的参数,即 nanoGPT 这里声明的 self.weight 与 self.bias,它相当于把学习的主动权交给网络,在梯度的反向传播中,可学习的两个参数也会进行更新,完整公式为:
2.2 Pre-LN 与 Post-LN
LayerNorm 根据进行计算的时点,分为两种:Pre-LN 和 Post-LN。如果我们将 Transformer Block 分为两个 Part,即:Self-Attention 与 FFN。
Pre-LN 代表的是先做 Norm,再做 Part 本身的处理,最后再做残差连接。对应的形式化表示为:
Post-LN 代表的是先做每个 Part 先做本身的处理,接着连接残差,最后再做 Norm。对应的形式化表示为:
经典论文《Attention Is All You Need》中采用的是 Post-LN,但已经被 Pre-LN 所取代,两种方式的演变以及有关梯度消失/爆炸的讨论可参见前述的博客分析,这里不再展开。
考虑一种非常现实的场景,如果不做 LayerNorm,而某些 token 的 embedding 数值特别大,会导致它在计算得到 Scaled Attention Score 矩阵中的值非常大,经过 Softmax,这个 token 在 probs 中的权重就会特别高,甚至逼近 1。到了反向传播的时候,由于 Softmax 的曲线在自变量极大时,几乎平行于 \(x\) 轴,这时梯度几乎为 0,导致了梯度消失,严重影响收敛。
2.2.1 LayerNorm 的直观作用
用一个简单的例子来说明 LayerNorm 的作用,假设我们有两个 token,它们的 embedding 维度 \(V=3\):
- Token A:\([1, 2, 3]\)
- Token B:\([100, 200, 300]\)
对于 Token A:
- 均值 \(\mu_A = \frac{1+2+3}{3} = 2\)
- 方差 \(\sigma_A^2 = \frac{(1-2)^2 + (2-2)^2 + (3-2)^2}{3} = \frac{2}{3} \approx 0.667\)
- 标准差 \(\sigma_A \approx 0.816\)
- 归一化结果:\(\frac{[1-2, 2-2, 3-2]}{0.816} = \frac{[-1, 0, 1]}{0.816} \approx \mathbf{[-1.22, 0, 1.22]}\)
对于 Token B:
- 均值 \(\mu_B = \frac{100+200+300}{3} = 200\)
- 方差 \(\sigma_B^2 = \frac{(100-200)^2 + (200-200)^2 + (300-200)^2}{3} = \frac{20000}{3} \approx 6666.67\)
- 标准差 \(\sigma_B \approx 81.65\)
- 归一化结果:\(\frac{[100-200, 200-200, 300-200]}{81.65} = \frac{[-100, 0, 100]}{81.65} \approx \mathbf{[-1.22, 0, 1.22]}\)
可以得到结论:Token A 和 Token B 经过 LayerNorm 后,结果一模一样。 那个原本数值极大的 Token B,它的量级被其自身同样巨大的标准差 \(\sigma\) 给完全抵消了。
2.3 LayerNorm 的实现
回到代码本身,forward 中只有一句,用到了 torch 的这个函数:torch.nn.functional.layer_norm(_input_, _normalized_shape_, _weight=None_, _bias=None_, _eps=1e-05_)
参考官方的 api 文档,layer_norm 会在输入数据 _input_ 的最后 D 个维度进行均值和标准差的计算,而 D 的数值取决于 _normalized_shape_ 而不等于 _normalized_shape_,实际上 D = len(normalized_shape)。nanoGPT 这里传入 self.weight.shape 的值为 torch.Size([ndim]),len(self.weight.shape)为 1,所以是从最后一个维度(即 \(D\))进行均值与标准差的计算。这只是为了符合 API 的规定,没有太多值得学习的内容,因为如果更换 API 可能又是新的写法。
对于老版本的 torch,torch.nn.LayerNorm 类没有提供不使用 bias 的方法,只提供一个选项,要么同时使用 weight 和 bias,要么同时不使用,所以 Karpathy 才会自己手写一个支持开关 bias 的自定义 LayerNorm 类。
老版本 torch 中的 nn.LayerNorm 可以简单理解为F.layer_norm + nn.Parameter套壳的参数。计算图的生成主要看是否发生了数学运算,与编程语言的封装没有关系,F.layer_norm 和 nn.LayerNorm 生成的计算图完全一样。二者的差异在于 F.layer_norm 是一个纯函数,本身不管理状态。其定位是简单的一次性计算,通常是无状态的,使用的 tensor 也通常设置 requires_grad = False,所以在自动求导时虽然会计算梯度,但并不会调整参数。因为优化器并不能通过遍历模型的参数感知到这些没有注册的 tensor。
requires_grad=True使得 torch 可以在loss.backward()计算 tensor 的梯度;而nn.Parameter将触发nn.Module的拦截机制,将这个成员记录到_parameter的字典中(注册),变成模型的一部分,使得后续optimizer.step()时根据梯度进行参数更新。
nn.LayerNorm 会自动管理所有的参数,默认设置 requires_grad=True,且注册为模型的一部分,不需要像 F.layer_norm 一样手动声明和管理 weight 和 bias。因此在 Kaypathy 手动实现的 LayerNorm 中,虽然同样使用的是 F.layer_norm,为了可学习,通过 nn.parameter 套壳,这样就意味着 weight 和 bias 都是 requires_grad=True,既会计算梯度,也会在梯度反向传播时进行参数调整(学习)。
有一种很常见的场景会将 tensor 声明为
nn.Parameter的同时设置requires_grad=False,即微调已有模型。设置特定层的requires_grad=False相当于“冻结”这些层的参数,让它们不随着训练而更新。当梯度反向传播时,torch 会跳过它们,同时节省了显存和时间。
3. 核心模块 CausalSelfAttention
CausalSelfAttention 源码
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
3.1 模块初始化 __init__
assert config.n_embd % config.n_head == 0
最开始做一道防御,要求总的 embedding 维度能够被头的数量整除,这是很常规的做法,我们不仅要均匀将 embedding 空间的信息分到每个头,还要在最后进行拼接和混合。
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
相比我们重复声明Q、K、V对应的三个权重矩阵,这里一口气声明为3 * config.n_embd,对算子进行融合,后续 GPU 只需要计算一次。更详细的讨论可以参见前置的博客。
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
__init__ 阶段作用之一是提前将需用到的网络一次性进行声明。这一步声明的 c_proj 是为了将后续每个头分得的 embedding 维度信息进行一次融合。通过这个全连接层,信息将不仅仅是简单的拼接。
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
有利于防止过拟合的 Dropout 层;全局可用的头的数量 n_head;输入数据的 embedding 特征空间的维度数 n_embd;启用 Dropout 层的开关,因为 Dropout 层只在训练阶段有用,推理和测试阶段通常会启用所有节点进行工作,否则可能造成结果不稳定。
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
这段代码逻辑稍显复杂,主要用到了两个知识:torch.nn.functional.scaled_dot_product_attention(简称“SDPA”)以及register_buffer。
这里尝试使用的 SDPA 在当时是一个实验性的新特性,后来才随着 PyTorch 2.0 正式上线。简单来说,它在底层实现了更高效的下三角掩码,也就是前面提到的 Causal Mask。
- SDPA 接口底层通常包含三种实现机制(引擎):Flash Attention、Memory-Efficient Attention(基于 xFormers,Meta 制作)、Math(兜底,最基础的 C++/CUDA 标准实现);前两种机制都是为了解决访存瓶颈的问题,通过数学公式推理,实现了不需要将完整矩阵加载到 SRAM 就能完成大矩阵运算的优化;
由于 SDPA 接口只在高版本 PyTorch 提供,nanoGPT 在检测到版本不匹配时还提供了另一种通过主动构造下三角掩码矩阵的手写实现。
- 我们在做 Causal Mask 的时候,操作上是将下三角掩码矩阵逐元素加到相同 shape 的矩阵上,本质上相当于 bias 操作(\(Output = \omega Input +bias\)),所以 Karpathy 将其命名为 bias(也是延续了 OpenAI 初代 GPT 代码的命名习惯);
config.block_size指的并不是 \((B, L, D)\) 中的 Sequence LengthL,而是最大支持的上下文长度,即位置矩阵wpe的第一个维度(另一个wte指的是由词汇到 embedding 的转换关系);torch.ones(config.block_size, config.block_size)得到 \([block\_size, block\_size]\) 形状的全 1 矩阵之后,下一步通过torch.tril得到全 1 的下三角矩阵(triangle lower);最后为了匹配 \([B, H, block\_size, block\_size]\) 的形状,因此做了一次 view 操作;后续在 forward 过程中,右上角的 0 会被替换为 \(-\infty\)。这一步其实是个工程上的优化,即一次内存申请,后续重复利用,理论上每次使用时再进行内存申请也是可以的。
再回顾一下,防止混淆。
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)才是需要训练的参数,即 \(W_Q\), \(W_K\), \(W_V\) 三个权重矩阵,算子融合后的这个矩阵是固定的。而对应产生的 Q、K、V 只是中间数据,会随着输入数据 L 的变化而在 shape 上发生变化,例如 \(X(B, L, D) \cdot W_Q(D, D) = Q(B, L, D)\)。
之所以不直接用 self.bias 来声明,而要用 self.register_buffer 来声明,是因为:
- 这个矩阵属于张量,不是超参(例如
n_dim或者head_num这种标量),也不是函数,张量必须注册(Register),标量只会在需要的时候传递到 GPU; - 这个矩阵不需要参与 学习/参数更新(
torch.nn下的模块除非明确指定,均会参与学习); bias所从属的 class 在实例化之后,当调用.to(device)时,bias能自动跟随模型移动到不同设备或者跟随模型保存(state_dict),而张量经过注册才能跟随模型移动或保存;
nn.Module内部维护了两个机器重要的字典:前面提到的_parameters和_buffers;如果只是通过self.bias = torch.tril(...)来声明,那么这个张量其实游离在这两个字段之外,只是 Python 对象的一个普通属性, PyTorch 底层的 C++ 引擎在处理这个模型实例时看不到bias这个变量,register_buffer的作用便是将bias注册到_buffers中,让底层的 C++ 引擎接管它的生命周期。
3.2 前向传播forward
B, T, C = x.size()
读取输入数据的 shape(对应我们前面说的 \((B, L, D)\),表达的是相同的意思),这里的 \(C\) 就是 \(n\_embd\),后续会被均分给每一个 head;
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
通过算子融合,计算 Q、K、V 矩阵,这样 GPU 只需要读取一次数据并计算。接着通过 view 拆分头,以及换轴,使得头与头之间的计算互不干扰。更详细的讨论可以参见前置的博客。
if self.flash:
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C)
高版本的 PyTorch 提供了基于 FlashAttention 的 SDPA 实现,所以优先使用高效率 API。如前所述,如果不支持 FlashAttention,那么就通过手写实现,即:
需要注意的是:att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf')) 中的 T 与转置没有关系,是从前面的B, T, C = x.size() 中获取的,本质上是 L。__init__ 中声明时,使用的是 config.block_size,而不是 L。这里是为了切片得到当前长度大小的下三角矩阵,接着利用 == 0 的判断条件,将符合条件的位置均替换为\(-\infty\),torch 的 API 语法要求如此。
# 两次 dropout
#···第一次在 softmax 之后
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
#···第二次在对所有 head 进行连接之后
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.resid_dropout(self.c_proj(y))
forward经历了两次 Dropout,第一次是作用在 Softmax 之后、与 Value 矩阵相乘之前的注意力得分矩阵。Softmax 之后的矩阵行总和为 1,这一次 dropout 的目的是为了随机让某些词之间的注意力权重归零,迫使模型在提取信息时,不要“过分依赖/过度关注”某一个特定的词而忽略了更通用的上下文信息,换句话说,学会在没有某些关键词时也能掌握上下文的信息;
第二次是在所有头注意力合并之后(注意所有头拼接之后需要经过一个全连接层 self.c_proj 进行融合),残差连接之前。目的是为了防止模型过度依赖特定的神经元(有概率屏蔽掉权重很大的超级神经元)。相当于在提取总结时,随机关掉几个神经元,迫使剩下的神经元都参与决策,确保剩下的神经元都具备独立的理解能力。
第二次 Dropout 属于标准做法,即在全连接层(nanoGPT 通常采用投影层的说法,本质是同一个东西,表达的是从
input_dim投影到output_dim)之后,残差连接之前做一次 Dropout。
4. MLP 与 Block
4.1 全连接层 MLP
nanoGPT 的 MLP(Multi-Layer Perception,多层感知机)等同于 FFN(Feed-Forward Network)。指的都是 MHA 之后的特征加工操作,也就是 \(Z\) 矩阵(\(probs \times V\))之后的记忆。
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
这是一个标准的实现,将输入数据 x 的维度放大 4 倍(\(W_1 X + b_1\)),然后接激活函数 \(GeLu\),再降维回去(\(ActivationW_2 + b_2\)),注意这里第二次全连接,因为这里是 FFN 的输出,我们需要保证数据的完整分布,之后不再需要激活函数了,等着做残差连接。即“中间非线性,两头线性”。同样的,在全连接层之后做一次 Dropout 防止过拟合。
从 MLP 的设计来看,nanoGPT 其实挺统一的,最后的一层全连接层才叫 proj(投影层),并且也在最后一层全连接之后做 Dropout。查阅资料发现,这属于优秀开源代码的一种命名实践,虽然都是全连接层,但是 fc 通常表示模块的入口,职责是打破现有的维度,去进行复杂的计算;而 proj 通常表示模块的出口,目的是规范输出的维度,确保数据能够安全地向外融合。
无论是 MLP 还是 CausalSelfAttention,都是以一种模块(nn.Module,大模块可以嵌套小模块)的形式设计。绝不能称之为层或者节点。
4.2 完整的 Block 组装
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
从 LayerNorm 到 CausalSelfAttention,接着到 MLP,现在底层准备已经结束,就到了打包成 Block 的环节。从 Block 的结构可以看出,这显然是更现代的 Pre-LN 的实现:
- Part A - SelfAttention:先 Norm,再做 Attention,接着残差连接,然后进入Part B;
- Part B - FFN:先 Norm,再做 FFN/MLP,接着连接残差,然后作为该模块的输出。
0 条评论